
1. 선형 회귀 모델
선형회귀
선형 회귀식을 활용한 모델. 선형 회귀 모델을 훈련한다는 것은 훈련데이터에 잘 맞는 모델 파라미터,
즉 회귀계수를 찾는 것이다.
https://www.kaggle.com/werooring/ch5-linear-regression
[ch5] Linear Regression
Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
www.kaggle.com
2. 로지스틱 회귀 모델
로지스틱 회귀
선형회귀방식을 응용해 분류에 적용한 모델
스팸 메일일 확률을 구하는 이진분류문제에 로지스틱 회귀를 사용할 수 있다.

3. 결정트리
분류와 회귀문제에 모두 사용가능한 모델

https://www.kaggle.com/werooring/ch5-decision-tree
[ch5] Decision Tree
Explore and run machine learning code with Kaggle Notebooks | Using data from No attached data sources
www.kaggle.com
불순도(impurity): 한 범주 안에 서로 다른 데이터가 얼마나 섞여 있는지 나타내는 정도
엔트로피(entropy): 불확실한 정도
정보 이득(information gain): 1 - 엔트로피
지니 불순도(gini impurity): 지니 불순도 값이 클수록 불순도가 높고 작을수록 불순도가 낮다.
4. 앙상블 학습
- 다양한 모델이 내린 예측 결과를 결합하는 기법. 앙상블 학습을 활용하면 대체로 예측 성능이 좋아진다. 과대적합 ㅏㅇ지 효과도 있다.
- 보팅(voting): 서로 다른 예측 결과가 여러 개 있을 때 개별 결과를 종합해 최종 결과를 결정하는 방식
- 하드보팅: 다수의 분류기 간 다수결로 최종 class 결정
- 소프트보팅: 다수의 분류기들의 class 확률을 평균하여 결정
- 배깅(bagging): 개별 모델로 예측한 결과를 결합해 최종 예측을 정하는 기법. '개별 모델이 서로 다른 샘플링 데이터를 활용'한다는 점이 특징
- 부스팅(boosting): 가중치를 활용해 분류 성능이 약한 모델을 강하게 만드는 기법
[참고]
Classification 2. 앙상블 학습(Ensemble Learning) - Voting과 Bagging
권철민 강사님의 '파이썬 머신러닝 완벽 가이드'을 학습하고 정리한 것입니다. 배우는 중이라 잘못된 내용이 있을 수 있으며 계속해서 보완해 나갈 것입니다. :)) 앙상블 학습이란, 앙상블 학습
libertegrace.tistory.com
머신러닝 - 11. 앙상블 학습 (Ensemble Learning): 배깅(Bagging)과 부스팅(Boosting)
앙상블(Ensemble) 앙상블은 조화 또는 통일을 의미합니다. 어떤 데이터의 값을 예측한다고 할 때, 하나의 모델을 활용합니다. 하지만 여러 개의 모델을 조화롭게 학습시켜 그 모델들의 예측 결과들
bkshin.tistory.com
5. 랜덤 포레스트 random forest
결정트리를 배깅방식으로 결합한 모델
나무가 모여 숲을 이루듯 결정트리가 모여 랜덤 포레스트를 구성한다. 분류와 회귀문제에 적용가능

6. XGBoost
성능이 우수한 트리기반 부스팅 알고리즘
랜덤포레스트는 결정트리를 병렬로 배치하지만 (배깅 방식)
XGBoost는 직렬로 배치해 사용한다. (부스팅 방식)
직전 트리가 예측한 값을 다음 트리가 활용해서 예측값을 조금씩 수정할 수 있다.
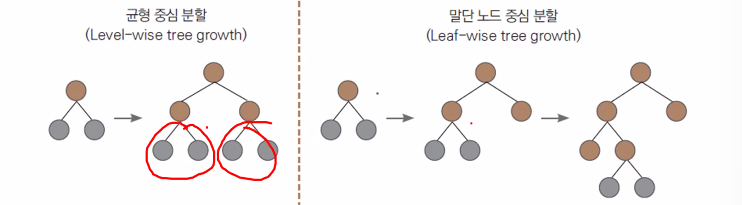
7. LightGBM
- XGBoost와 성능은 비슷하지만 훈련속도가 더 빠른 모델. 마이크로소프트에서 개발
- 말단 노드 중심으로 예측 오류를 최소화하게끔 분할한다.
- 말단 노드 중심으로 분할하면 균형을 유지할 필요가 없으니 추가 연산이 필요없다.
- 균형 중심 분할보다 빠르다.
하지만 데이터개수가 적을 때는 과대적합되기 쉽다는 단점 -> 과대적합 방지용 하이퍼파라미터를 조정해야한다.
> 하이퍼파라미터 최적화
하이퍼파라미터
:사용자가 직접 설정해야 하는 값
모델이 좋은 성능을 내려면 어떤 하이퍼파라미터가 어떤 값을 가지면 좋을지 찾아야 한다.
1. 그리드서치
가장 기본적인 하이퍼파라미터 최적화 기법
주어진 하이퍼파라미터를 모두 순회하며 가장 좋은 성능을 내는 값을 찾는다. 모든 경우의 수 탐색하기 때문에 시간이 오래 걸린다.
2. 랜덤서치
- 하이퍼파라미터를 무작위로 탐색해 가장 좋은 성능을 내는 값을 찾는 기법
3. 베이지안 최적화
사전 정보를 바탕으로 최적 하이퍼파라미터 값을 확률적으로 추정하며 탐색하는 기법
더 빠르고 효율적으로 찾아준다. 코드도 직관적이며 사용하기 편하다.

'2022 K Data 청년 캠퍼스 > ML&DL' 카테고리의 다른 글
| [DL] 딥러닝 기초 용어 정리 (0) | 2022.07.20 |
|---|---|
| 데이터 시각화 (0) | 2022.07.19 |
| [ML] 3. 교차 검증 (0) | 2022.07.19 |
| [ML] 2. 데이터 인코딩과 피처 스케일링 (0) | 2022.07.19 |
| [ML] 1. 분류와 회귀 (0) | 2022.07.19 |